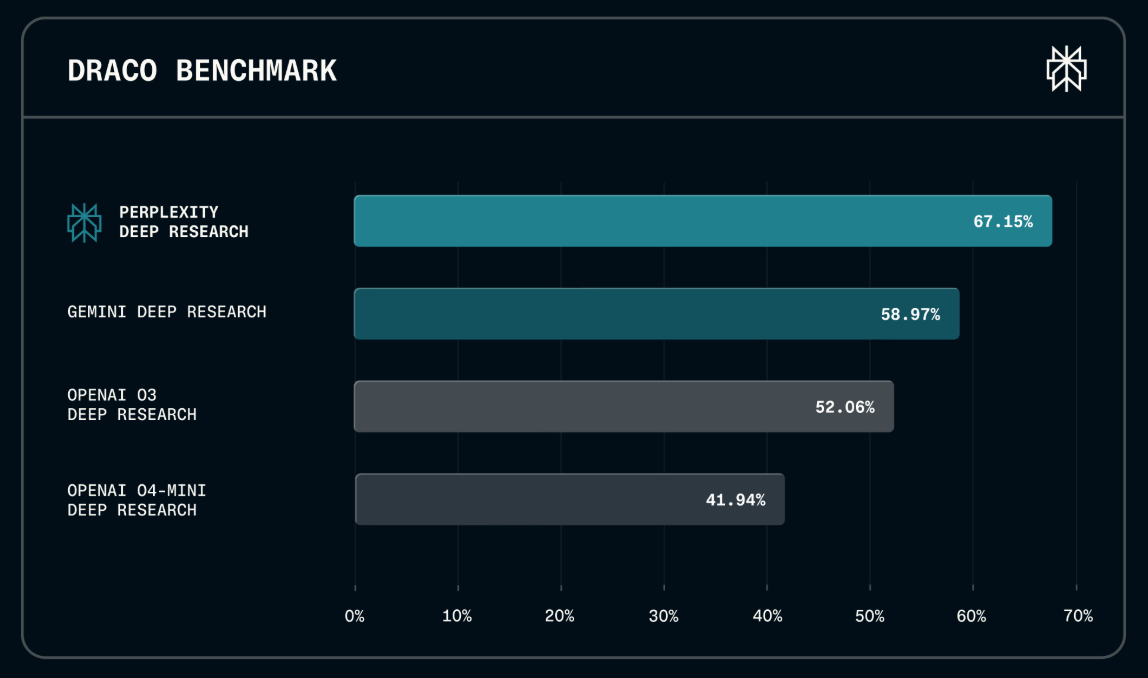
Perplexity AI launched DRACO, an open-source benchmark evaluating research agents via 100 tasks from...
The AMW Read
Perplexity (a key player in research/search) is updating the agentic evaluation landscape with a production-grounded benchmark, but this is an incremental tool release rather than a structural shift.
NoveltySignificance
AI Agents · Player Map
Perplexity AI launched DRACO, an open-source benchmark evaluating research agents via 100 tasks from real user queries. Spanning 10 domains, Perplexity leads with 89.4 percent accuracy in Law and 82.4 percent in Academic research. Shifting from synthetic puzzles to production-grounded data creates a rigorous standard for multi-step reasoning. This systemic evolution forces the AI industry to prioritize factual depth over conversational fluency. 🚀