MetaCrowd launches beta of AI detection solution 'Geuljajuk' for academic papers
The AMW Read
New entrant in AI detection sub-segment with a differentiated approach (pre-LLM training data, layered scoring, on-premise) that updates the player map; significance is sub-segment only as the product is in beta.
MetaCrowd launches beta of AI detection solution 'Geuljajuk' for academic papers
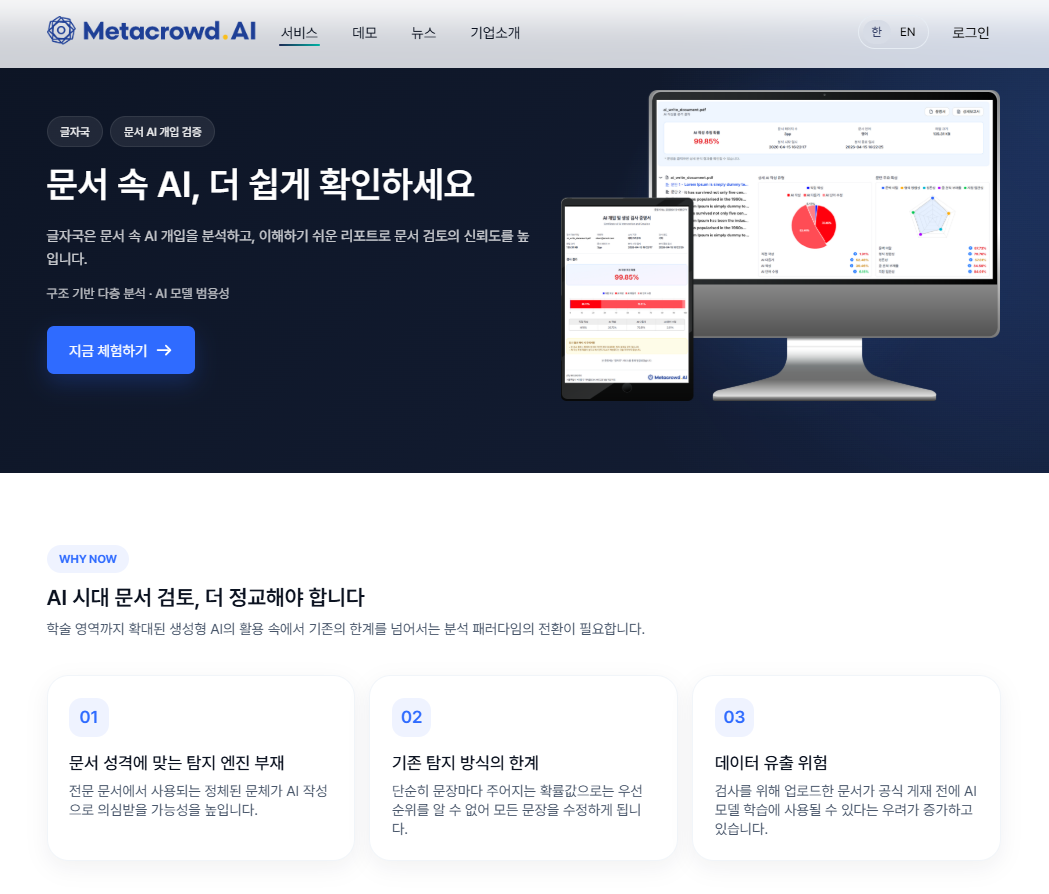
South Korean AI detection startup MetaCrowd has released the beta version of 'Geuljajuk', an AI detection solution specialized for academic and research papers. The tool classifies AI involvement in documents into three levels, providing probability scores for each tier across document, paragraph, and sentence layers. It also identifies paragraph-level AI density to help evaluators focus on the most relevant sections. MetaCrowd trained the model exclusively on human-written papers from the pre-generative AI era to reduce false positives—an acknowledged weakness in existing detectors that often flag polished academic prose as AI-generated.
This launch updates the growing market for AI authorship verification, particularly in academic publishing and research integrity. While many detection tools position themselves as general-purpose, Geuljajuk targets a specific vertical need: the ability to distinguish legitimate AI assistance from misuse in scholarly work. The on-premise deployment model addresses institutional data-security concerns, and the company plans to tailor results for universities, research institutes, and government agencies. The approach echoes the broader market pattern of specialization by sector and compliance posture, as institutions increasingly demand more nuanced, context-aware detection rather than binary AI-or-not classifiers.
MetaCrowd's timing aligns with a shift in editorial policies at major journals like Science, which are moving toward tiered AI-use frameworks (permitted, conditional, prohibited) rather than outright bans. This creates both demand and complexity for detection tools that must map onto varied policy regimes. The company's claim of training exclusively on pre-LLM human text aims to directly counter the high false-positive rates that have undermined trust in earlier detection products. Success in this niche will depend on whether Geuljajuk can maintain accuracy as models evolve and whether institutions adopt the tool as part of their review workflows.