
1. Introduction: The Inflection Point in Spoken Dialogue Systems
The history of Human-Computer Interaction (HCI) has long been characterized by a rigid, transactional cadence. Since the inception of modern voice assistants, the dominant interaction model has been the "turn-taking" system, often derisively referred to as the "walkie-talkie" paradigm. In this model, the user speaks, the machine detects silence, processes the input, and only then generates a response. This serialization of tasks-Speech-to-Text (ASR), Natural Language Understanding (LLM), and Text-to-Speech (TTS)-introduces inevitable latency, typically ranging from two to five seconds. While functional for command-and-control tasks, this architecture fundamentally fails to replicate the fluidity, overlap, and emotional nuance of human conversation.
The release of PersonaPlex by NVIDIA Research represents a decisive break from this legacy. By introducing a real-time, full-duplex speech-to-speech architecture, PersonaPlex allows for simultaneous listening and speaking, effectively mimicking the cognitive processing of a human interlocutor who listens while preparing a response. This report provides an exhaustive analysis of the PersonaPlex system, responding to the specific request to analyze its introductory demonstrations and investigate its technical underpinnings. We will deconstruct the video demonstrations referenced in the user query, dissect the proprietary "Hybrid System Prompt" architecture, and evaluate the model's performance against the newly established FullDuplexBench standards.
This document serves as a definitive technical reference, synthesizing data from technical papers, repository documentation, and benchmark analyses to provide a granular view of how PersonaPlex achieves its "impossible" combination of high-fidelity role adherence and sub-perceptual latency.
2. Deconstructing the Introductory Material: Analysis of the Video Demonstrations
The user’s query explicitly refers to an introductory video showcasing PersonaPlex. Based on the research data available, this material comprises a series of carefully orchestrated demonstrations designed to highlight specific architectural capabilities that traditional models lack. We analyze these scenarios-specifically the "First Neuron Bank" and "Mars Mission" segments-as evidence of the model's underlying dual-stream processing capabilities.
2.1 The First Neuron Bank Scenario: Simultaneous Slot-Filling and Empathy
In the first demonstration, the model adopts the persona of Sanni Virtanen, a customer service agent at "First Neuron Bank". The scenario involves a customer frustrated by a declined transaction of $1,200 at a Home Depot in Miami, Florida.
Behavioral Analysis: The user is depicted as agitated, a common stress test for voice AI. Unlike standard IVR (Interactive Voice Response) systems that would wait for a pause to process the "anger," PersonaPlex is shown to process the user's prosody (tone of voice) in real-time. The model maintains the persona of Sanni-likely conditioned with a specific accent via the voice prompt-and navigates the strict banking protocol of identity verification without breaking the conversational flow.
Technical Implication: This demonstrates the model's Hybrid Prompting capability. The text prompt rigidly defines the logic (IF transaction declined -> THEN verify identity), while the audio prompt defines the vocal texture. The model’s ability to "listen while talking" is crucial here; if the user interrupts Sanni to correct a detail, the model can halt its output immediately, a function of its full-duplex nature.
2.2 The Space Emergency Scenario: Generalization Under Pressure
The second pivotal demonstration features a character named Alex, an astronaut facing a reactor core meltdown on a mission to Mars.
Behavioral Analysis: Alex is required to convey urgency and technical precision. The prompt describes a catastrophic failure, and the model must explain the physics of the meltdown while requesting technical assistance.
Technical Implication: This scenario serves as a stress test for Out-of-Distribution (OOD) generalization. The training data for PersonaPlex (primarily the Fisher Corpus of telephone conversations) does not contain discussions about Martian reactor cores. The success of this demo proves the efficacy of the Helium language backbone. The model leverages the semantic world knowledge embedded in the Helium LLM to "hallucinate" a coherent technical explanation, while the PersonaPlex architecture ensures the delivery matches the emotional urgency of the audio prompt. It confirms that the system is not merely a "parrot" of its training data but a reasoning engine capable of role-play.
2.3 The Casual Conversation Scenario: Backchanneling Mechanics
A third, more subtle demonstration involves a casual chat where the user discusses mundane topics like dining habits.
Behavioral Analysis: Here, the model inserts short affirmations-"uh-huh," "right," "yeah"-while the user is still speaking.
Technical Implication: This highlights the Backchanneling capability. In traditional half-duplex systems, the bot is deaf while speaking and mute while listening. PersonaPlex, however, predicts the appropriate moments to insert these phatic expressions based on the user's pause duration and prosodic contour, significantly enhancing the perception of "presence".
3. Technical Identity: The Moshi-Helium Synergy
To understand precisely what PersonaPlex is, we must look beyond the branding and examine its architectural lineage. The research confirms that PersonaPlex is not a clean-slate architecture but a sophisticated evolution of the Moshi framework developed by Kyutai, augmented with NVIDIA’s proprietary prompt engineering and training strategies.
3.1 The Moshi Architecture Foundation
The structural skeleton of PersonaPlex is the Moshi architecture. Kyutai’s Moshi was a breakthrough in its own right, proving that a single transformer could model a full-duplex conversation by treating the "user" and "agent" as two parallel streams of tokens.
Unified Transformer: Unlike cascaded systems that hand off data between discrete models (ASR -> LLM -> TTS), Moshi (and thus PersonaPlex) processes all modalities within a single transformer context window.
The Limitation of Moshi: The original Moshi model, while fluid, was "hard-coded" to a specific voice and personality. It lacked the flexibility to switch from a "friendly assistant" to a "stern banker" without retraining. NVIDIA’s contribution was to unlock this architecture, enabling dynamic conditioning.
3.2 The Helium Language Backbone
The cognitive core of PersonaPlex is Helium, a 7-billion parameter language model. It is critical to distinguish this from the 2B parameter "Helium-1" preview released by Kyutai for edge devices. PersonaPlex utilizes a larger, more capable variant (7B) to support the complex reasoning required for enterprise tasks.
Role of Helium: While the Moshi components handle the form of the conversation (timing, audio generation), Helium handles the substance (logic, facts, reasoning).
Integration: In the architecture, Helium’s text tokens are interleaved with the audio tokens. The model effectively employs an "Inner Monologue," predicting the text response first (the thought) and then generating the corresponding audio tokens (the speech). This ensures that the speech is not just phonetically sound but semantically coherent.
3.3 The Mimi Neural Audio Codec
Traditional Large Language Models operate on text tokens. To apply this transformer architecture to sound, audio must be "tokenized." PersonaPlex utilizes the Mimi neural audio codec for this purpose.
Compression and Tokenization: Mimi compresses continuous audio waveforms (24kHz sample rate) into discrete tokens. It uses a combination of Convolutional Neural Networks (ConvNet) and Transformers in its encoder and decoder.
Residual Vector Quantization (RVQ): While not explicitly detailed in every snippet, neural codecs like Mimi typically use RVQ to represent high-fidelity audio with a compact vocabulary of tokens. This allows the Helium backbone to predict audio tokens autoregressively, just as it would predict the next word in a sentence.
Dual-Stream Processing: The Mimi codec feeds two distinct channels into the model: one for the user's incoming audio and one for the agent's outgoing audio. This separation is what enables the full-duplex capability-the model can "read" the user channel while "writing" to the agent channel simultaneously.
4. The Core Innovation: Hybrid Prompting Architecture
The defining innovation of PersonaPlex-and the feature that separates it from its predecessor Moshi-is the Hybrid System Prompt. This mechanism solves the historical trade-off in voice AI: the choice between the naturalness of end-to-end models and the controllability of cascaded systems.
4.1 The Mechanism of Dual Conditioning
PersonaPlex is conditioned on two distinct inputs before a session begins. These inputs are processed jointly to define the agent's identity.
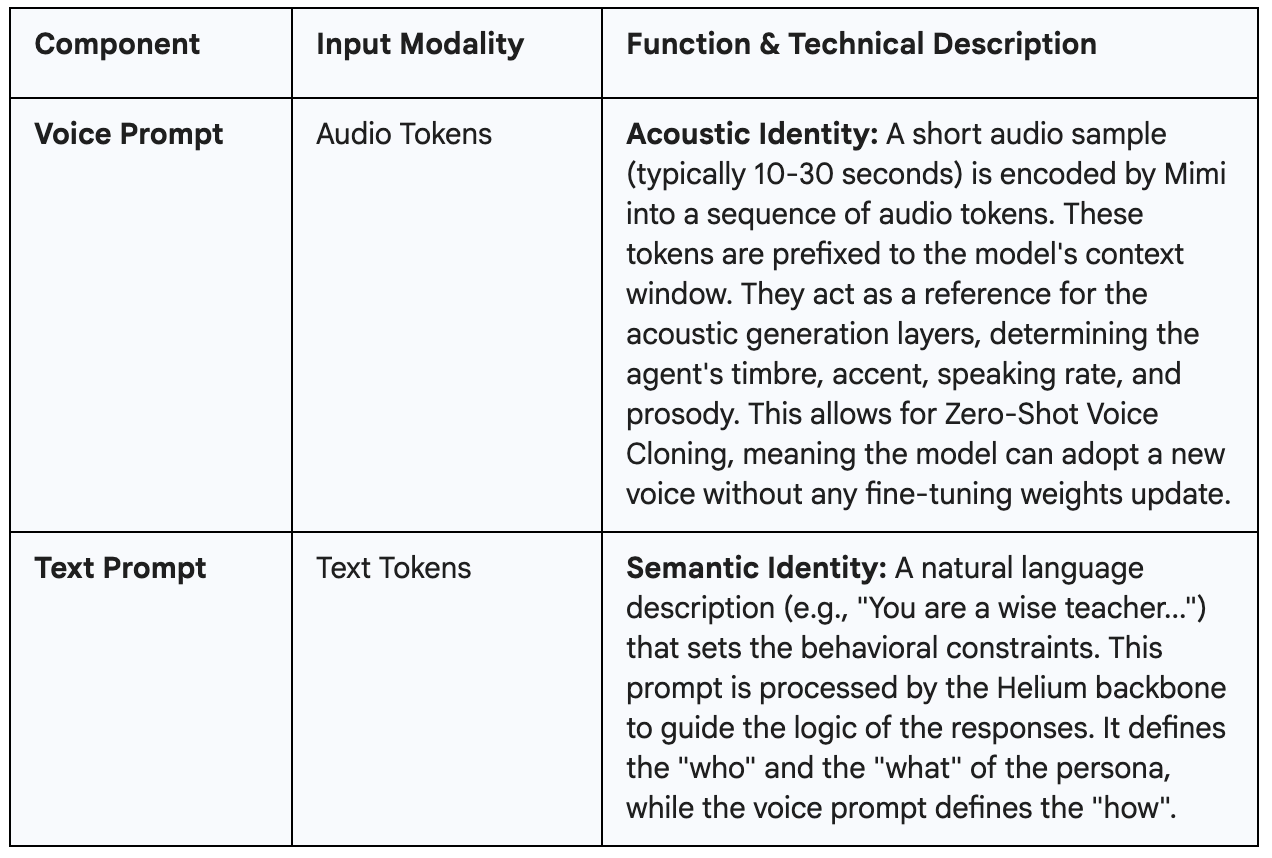
Semantic Identity: A natural language description (e.g., "You are a wise teacher...") that sets the behavioral constraints. This prompt is processed by the Helium backbone to guide the logic of the responses. It defines the "who" and the "what" of the persona, while the voice prompt defines the "how".
4.2 Solving the Impossible Choice
In previous generations of Voice AI, developers had to choose:
Cascaded Systems (ASR+LLM+TTS): Highly controllable (you can change the system prompt easily) but slow and robotic.
End-to-End Models: Fast and natural, but uncontrollable (the voice and personality were baked into the training data).
PersonaPlex's Hybrid Prompting merges these worlds. By treating the voice prompt as just another set of tokens in the context window, it allows for dynamic switching of voices. A developer can send a text prompt "Be a pirate" and an audio prompt of a gruff voice, and the model will synthesize a pirate persona with a gruff voice instantly.
4.3 Generalization Capabilities
The power of this architecture is further evidenced by its ability to generalize. The research highlights that the text and voice prompts are disentangled. A voice prompt from a calm speaker can be combined with a text prompt requiring an angry response, and the model attempts to synthesize "calm anger" or appropriately shift the prosody based on the semantic context of the text prompt. This disentanglement is crucial for creating rich, believable characters in gaming or nuanced agents in customer service.
5. Training Methodologies: The Synthesis of Real and Artificial
Training a model to listen and speak simultaneously requires a fundamentally different dataset than training a text-based LLM. A text LLM waits for a "stop" token; a full-duplex model must learn when to stop based on the rhythm of the conversation. NVIDIA employed a dual-source training strategy to teach PersonaPlex these complex dynamics.
5.1 The Fisher English Corpus: Learning to Be Human
To capture the subtle "dance" of conversation-interruptions, backchannels, breath pauses-NVIDIA utilized the Fisher English Corpus.
Dataset Profile: This corpus consists of approximately 1,217 hours of telephone conversations between strangers.
Why Fisher? Unlike audiobooks (one speaker, scripted) or broadcast news (formal, structured), Fisher contains messy, overlapping, spontaneous speech. It is the "ground truth" for how humans actually talk.
The Annotation Challenge: The raw Fisher audio has no labels explaining why a speaker laughed or interrupted. To solve this, NVIDIA used a "teacher" LLM (GPT-OSS-120B) to retrospectively analyze the conversations. The teacher model generated synthetic text prompts that would have produced such a conversation (e.g., "Speaker A is curious, Speaker B is hesitant"). This process, known as back-annotation, effectively turned raw audio into a supervised learning dataset, teaching PersonaPlex the causal link between a persona description and specific speech behaviors.
5.2 Synthetic Data: Learning to Follow Orders
While Fisher taught the model how to speak, it could not teach the model to follow strict enterprise protocols (which strangers on a phone call rarely do). To bridge this gap, NVIDIA generated a massive synthetic dataset.
Scale: Over 2,200 hours of synthetic dialogue.
Generation: Dialogues were scripted by advanced LLMs (Qwen-3-32B, GPT-OSS-120B) to cover specific domains like banking, healthcare, and technical support.
Rendering: These scripts were converted into audio using Chatterbox TTS and Dia (a multispeaker TTS capable of room tone and interruption simulation).
Purpose: This data anchors the model's behavior, preventing it from hallucinating or drifting off-topic-a common failure mode in pure end-to-end models. It enforces the "instruction following" capability seen in the Sanni Virtanen demo.
5.3 Acoustic Augmentation
To ensure the model didn't overfit to the synthetic voices, the training pipeline included acoustic augmentation. Voices from TortoiseTTS were manipulated using Praat (a phonetic analysis tool) to shift pitch and formants, creating a diverse "population" of synthetic speakers. This variety forces the model to learn a generalized representation of the human voice rather than memorizing specific TTS artifacts.
6. Performance Analysis: Benchmarking Full-Duplex Interaction
Evaluating a full-duplex model is notoriously difficult because standard metrics like Word Error Rate (WER) do not capture conversational timing. NVIDIA, therefore, relied on the FullDuplexBench and their own ServiceDuplexBench.
6.1 Latency Metrics
The most critical metric for a real-time system is latency.
End-to-End Latency: PersonaPlex achieves a practical response latency of ~257 milliseconds.
Psychophysics Context: Human conversational gaps typically average around 200ms. Latencies above 500ms are perceived as "lag," and latencies above 1 second break the illusion of intelligence. PersonaPlex’s performance places it squarely within the "natural" range, a feat previously unachievable with cascaded architectures.
Smooth Turn-Taking: The model's turn-taking latency is measured at 0.170 seconds, indicating it can seize the floor almost instantly when the user stops speaking.
6.2 Conversational Dynamics (FullDuplexBench)
This benchmark measures the model's ability to handle the flow of conversation.
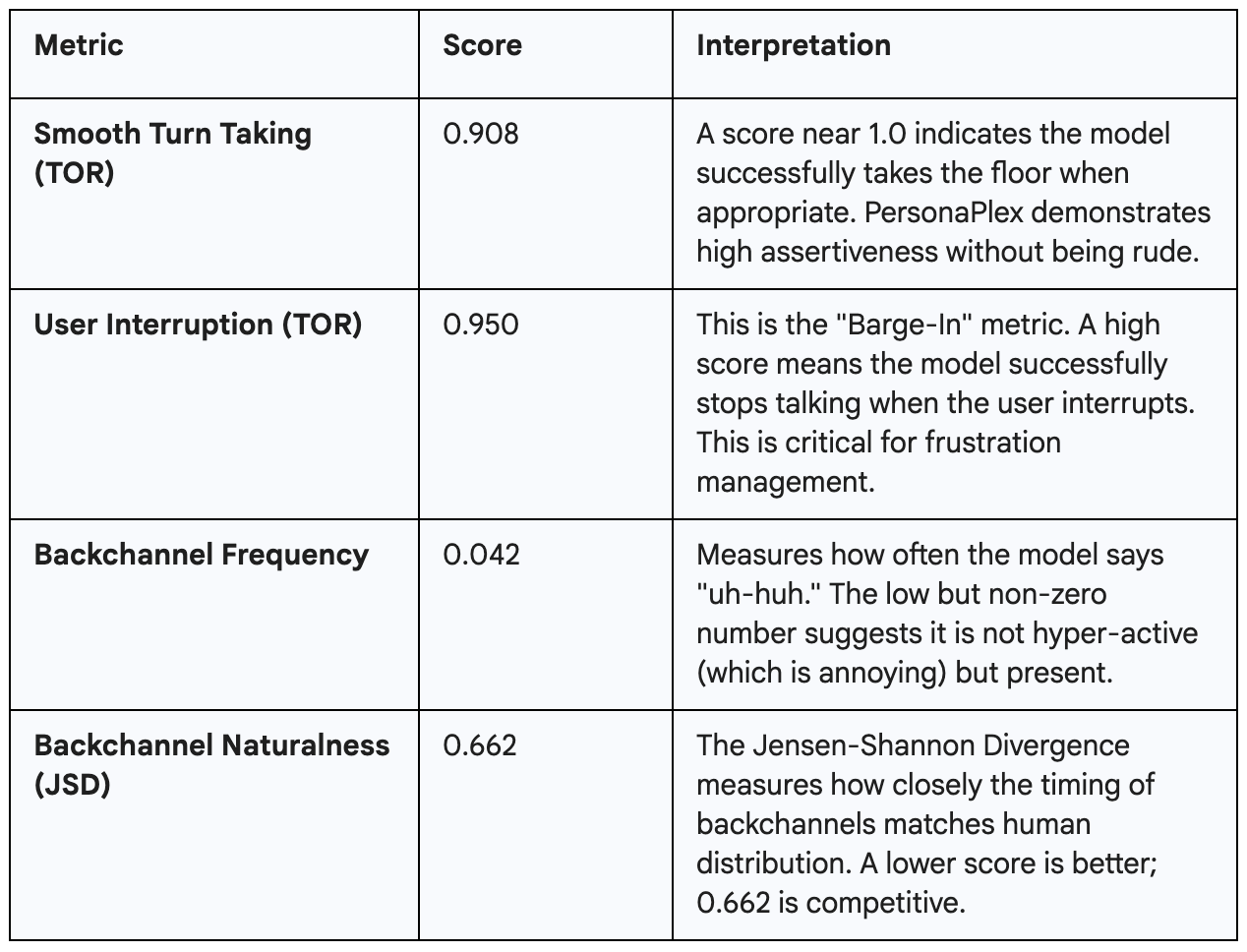
The Jensen-Shannon Divergence measures how closely the timing of backchannels matches human distribution. A lower score is better; 0.662 is competitive.
6.3 Task Adherence (ServiceDuplexBench)
To prove the model is enterprise-ready, NVIDIA evaluated it on ServiceDuplexBench, which tests proper noun recognition and protocol following.
Score: PersonaPlex scored 4.48 (out of 5).
Comparison: This is significantly higher than the base Moshi model (1.75) and Qwen-2.5-Omni (2.76). It is the only open model to approach the performance of the closed-source Gemini Live (4.73). This validates the efficacy of the synthetic training data in instilling rigorous logic into the fluid Moshi architecture.
7. Operational Requirements and Deployment
While PersonaPlex is an "open" model, its operational requirements are steep, reflecting its status as a bleeding-edge research artifact.
7.1 Hardware Infrastructure
The model is optimized for NVIDIA’s data center GPUs, specifically the Ampere (A100) and Hopper (H100) architectures.
The Blackwell Compatibility Issue: A notable operational hurdle was identified for users with the newest Blackwell (RTX PRO 6000) GPUs. The standard PyTorch installation does not support the sm_120 CUDA capability required by these chips.
The Fix: Users must manually install a specific nightly build of PyTorch (pip install torch... --index-url.../cu128) to enable compatibility. This detail, buried in GitHub issues, is critical for early adopters attempting to run the model on next-gen hardware.
7.2 Software Stack and Environment
Deployment involves a complex dependency tree:
Audio Codec: The libopus development library must be installed at the OS level (e.g., apt install libopus-dev) to support the Mimi codec's audio handling.
Inference Server: The model runs via a Python module (moshi.server).
Resource Constraints: For users without 80GB A100s, the system supports CPU offloading (--cpu-offload), though this reintroduces significant latency, effectively negating the real-time advantages of the architecture.
7.3 Licensing and Access Control
PersonaPlex is not "open source" in the traditional sense (e.g., MIT or Apache). It is released under the NVIDIA Open Model License Agreement.
Implications: While it allows for commercial use, it retains restrictions likely aimed at preventing abuse (e.g., deepfakes). Furthermore, the repository is gated; users must share their contact information with NVIDIA to access the weights. This "Open Weights, Restricted License" model is becoming standard for high-risk, high-capability AI models.
8. Strategic Market Implications and Future Outlook
The release of PersonaPlex signals a commoditization of high-end voice AI capabilities that were previously the exclusive domain of tech giants.
8.1 The Democratization of Empathetic AI
Until now, truly responsive, interruptible voice AI was a "walled garden" feature offered only by OpenAI (GPT-4o Realtime) or Google (Gemini Live). By releasing the weights of a 7B parameter model that rivals these proprietary services, NVIDIA has empowered smaller enterprises to build "empathetic interfaces." Companies can now host their own highly responsive agents on-premise, addressing the data privacy concerns that prevented banking and healthcare sectors from using cloud-based voice APIs.
8.2 The Rise of the Any-to-Any Token Economy
PersonaPlex validates the architectural thesis that everything can be a token. By successfully interleaving audio tokens and text tokens in a single stream, NVIDIA has proven that modality boundaries are artificial. The logical next step is the integration of video tokens, haptic tokens, or robotic control tokens into the same transformer stream. We are moving toward "Omni-Models" where a single neural network perceives and acts across all human senses simultaneously.
8.3 Ethical and Security Risks
The very feature that makes PersonaPlex powerful-Zero-Shot Voice Cloning-poses significant risks. The ability to clone a voice from a 10-second clip has profound implications for security (e.g., bypassing voice biometrics). While the license restricts malicious use, the open nature of the weights means that bad actors can technically bypass safeguards. The industry will likely see an accelerated arms race between neural voice synthesis and neural forgery detection (watermarking) in the coming years.
9. Conclusion
NVIDIA PersonaPlex represents a watershed moment in the evolution of conversational AI. It is not merely an incremental improvement but a fundamental architectural shift from serialized processing to full-duplex simultaneity. By hybridizing the fluid, biological dynamics of the Moshi architecture with the rigorous instruction-following capabilities of the Helium language model, NVIDIA has solved the "Walkie-Talkie" problem.
The ability to listen and speak at the same time, coupled with the capacity to instantly adopt any voice or persona via the Hybrid System Prompt, positions PersonaPlex as the new baseline for what users will expect from digital interactions. It marks the end of the era of "chatbots that speak" and the beginning of the era of true "empathetic interfaces"-systems that understand not just what we say, but how we say it, and respond with a presence that feels, for the first time, genuinely present.
For researchers and engineers, PersonaPlex offers a robust, open-weight platform to explore the frontiers of multi-modal interaction. For the broader industry, it serves as a signal that the latency barriers which once separated human and machine communication have effectively dissolved.